
予知保全に機械学習を導入したいものの、「具体的に何が変わるのか」「自社設備に本当に適用できるのか」が整理できず、稟議やPoC設計の段階で止まることは少なくありません。
特に、古い設備が混在する工場では、センサー後付けの可否やデータが取れる周期が分からず、必要な計測条件を決めきれないまま検討が長引きがちです。
予知保全における機械学習とは、振動・電流・温度などの状態データを継続的に測定し、設備が故障する前に対応するための判断手段です。人の勘に頼る保全や単純な閾値監視とは異なり、「いつもと違う数値の増え方・揺れ方」を捉えられます。
本記事では、製造業で機械学習が必要とされる背景から、導入メリットや現場導入までの具体的なステップを解説します。

製造業の予知保全で「機械学習」が必要とされている理由
予知保全に機械学習が求められる背景には、現場における「人・設備・コスト」の3つの制約があります。従来の保全手法だけでは、この3点で限界が出やすくなっています。
| 制約 | 現場の現状 | 機械学習で変わること |
|---|---|---|
| 人(技能承継) | 「音・振動の違和感」がベテランの退職で失われる | 違和感を数値データとして残し、判断基準を共有できる |
| 設備(監視の限界) | 24時間・大量データを人が見続けられない | データを常時監視し、「いつもと違う変化」を拾える |
| コスト(突発故障) | 突発停止で生産停止・納期遅延・信用低下が起きる | 予兆で先回りし、計画停止・交換時期を選べる |
この3つの制約が重なるほど、勘や経験に依存した保全や閾値監視だけでは回らなくなり、機械学習による予知保全を検討する必要性が高まります。
予知保全に機械学習を導入する4つのメリット

ここでは、機械学習を使うことで現場の保全業務がどう変わるのか、4つに分けてメリットを解説します。単なる技術的な利点ではなく、現場判断やコスト管理への影響を踏まえた検討の参考にしてください。
メリット1:ダウンタイムの削減
機械学習による予知保全は、故障が起きる前の異常検知をおこなう仕組みです。
例えば、モーターの振動データを継続監視し、通常と異なる変化傾向が出た段階でアラートを出します。
これにより、生産計画に影響の少ない時間帯で保全作業を組めます。突発的な設備の停止が減ることで、ライン全体の稼働率が安定するため、現場は「止められない保全」から「止め方を選べる保全」へ移行します。
メリット2:メンテナンスコストの最適化
従来の定期保全では、「壊れる前提」で部品を交換するため、まだ使える部品を廃棄していました。機械学習は、部品の状態変化から残り使用期間の目安を判断可能です。
例えば、軸受の振動増加傾向を分析し、限界が近づいた段階で交換します。これにより、部品の寿命を使い切りつつ、在庫部品を必要最小限に抑えられます。保全費用と在庫コストの両方を下げられる点が特長です。
メリット3:熟練技能の継承
機械学習モデルは、過去の正常状態と異常状態のデータを学習し、「いつもと違う状態」を数値で判断します。
これは、ベテランの経験則をモデルとして保存する行為に近く、若手作業員でもモデルの判定結果を基に保全判断ができるようになります。
例えば、「この振動の出方は軸受が怪しいので早めに点検する」といった一次判断を、一定の基準で揃えられます。判断基準が統一されるため、属人化を防ぎ、判断のばらつきも抑えやすいです。
メリット4:品質管理の向上
品質管理では、不良が出てから原因を追うと、影響範囲の切り分けに時間がかかります。結果として、追加検査や手直しが増え、良品率が下がりやすいです。
機械学習を使うと、設備の微細なガタつきや回転ムラといった変化を、製品の精度不良として表面化する前に検知できます。
品質に影響が出る前に点検・調整へ回せるため、不良の発生を抑え、歩留まり率の向上につながります。
予知保全に最適な機械学習アルゴリズムとは?
予知保全で使われる機械学習は一種類ではありません。
目的・データ量・現場で動かす条件(計算環境や運用不可)によって適した手法が変わります。
まずは下図をご覧ください。従来の機械学習とディープラーニングの違いは、「どこまでを機械に任せるか」です。
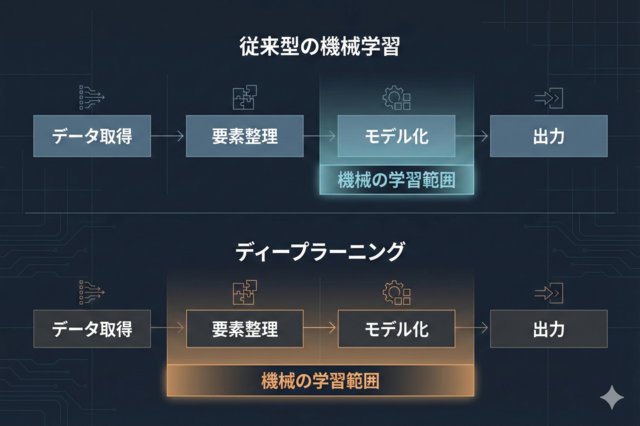
《機械学習の種類における違い》
- 従来の機械学習:「モデル化」が中心で、その前の「要素整理(異常の目印を決める作業)」を人が担う
- ディープラーニング:「要素整理〜モデル化」までをまとめて学習し、複雑なパターンを見つけやすい設計
それぞれの仕組みと向いているケースを具体的に整理します。
従来の機械学習の特徴と仕組み
従来の機械学習は、人が異常の目印を先に決めてから学習させる方法です。例えば、振動の特定周波数帯やRMS値、温度上昇の勾配などを指標にし、正常時と比べてずれたら異常と判定します。
計算量が小さいため、設備のそばに置く小型PCでも動かしやすいです。さらに「どの指標がどのくらいずれたからアラートが出たか」を説明しやすく、保全部門内の合意形成や現場への納得感につながります。
センサーが少ない設備や故障データが十分に集まっていない段階でも始めやすく、低コストでPoCを回したい場合に向いています。
ディープラーニング(深層学習)の特徴と仕組み
ディープラーニングは、人が目印を細かく設計しなくても、データの並びから「異常につながりやすいパターン」を見つける方法です。多数のセンサー値や画像データを同時に扱えます。
人の目や耳では捉えられない微細な予兆を拾える一方、学習に必要なデータ量が多く、高い処理能力を持つサーバーやクラウド環境が必要です。
画像検査を含む施設や、多項目センサーが絡む複雑な設備で、高い検知精度を求める場合に適しています。
機械学習による予知保全を導入する5ステップ

ここでは、現場導入までの流れを5ステップで整理します。
いきなり全設備を対象にせず、影響の大きい設備と特定の故障モードに範囲を絞ることが重要です。
【ステップ1】目的の明確化:どの設備の、どの故障を止めたいか?
最初に決めるべきは「どの設備の、どの故障を止めたいのか」です。「すべての故障」を対象にすると、必要なデータや判断基準が散漫になり、検証が進みません。
例えば、修理費が高い設備や、止まるとライン全体に影響する設備に絞ります。
対象を限定することで、取るべきデータと効果測定の指標が明確になり、社内説明もしやすくなります。
【ステップ2】データ収集・計測:振動・電流・温度など最適なセンサーの選定
次に「故障の兆しがどこに現れるか」を考え、計測項目を決めます。故障の種類によって、見るべきデータが変わるためです。
軸受の劣化なら振動、モーター負荷の異常なら電流、配管の詰まりや漏れなら圧力など、兆候が最も早く出るパラメーターを選びます。
重要なのは、単に測れる項目ではなく、故障の初期変化が出る場所にセンサーを設置することです。
【ステップ3】データ前処理・学習:特徴量の抽出とモデルの作成
収集データをそのまま学習させると、ノイズや外乱の影響で誤判定が増えます。まずは不要な揺らぎを除去し、異常の兆しが見えやすい形に整えます。
例えば、時間軸の振動データを周波数軸に変換し、異常に関連する周波数帯を抽出します。
この「どの情報を残し、どれを削るか」の設計が、モデル精度を大きく左右します。
【ステップ4】評価・検証:過去の故障データと照らし合わせて精度を確認
異常判定のモデルは、作って終わりではありません。過去の故障履歴と照らし合わせ、どれだけ正しく検知できるかを確認します。
評価では、「空振り(誤検知)」と「見逃し(未検知)」のバランスを調整します。
誤検知が多すぎると現場がアラートを信用しなくなり、通知を止められる可能性があります。一方、見逃しが多いと実際の故障を防げず、予知保全の効果が出ません。
現場で許容できるアラート頻度を決め、その範囲に収まるよう判定基準をチューニングします。
【ステップ5】現場実装・運用:クラウド・エッジ(現場設置型)の選定
最後に、異常判定を「設備のそばでおこなうか」「クラウド上でおこなうか」を決めます。
リアルタイムで停止制御や警報を出す必要がある設備では、機械のそばで即座に判定できるエッジ型が有効です。通信遅延に左右されず、その場で対応可能です。
一方、複数拠点の設備をまとめて分析したい場合や学習処理をおこなう場合は、クラウドが向いています。ただし、データのセキュリティや通信環境を前提に設計する必要があります。
まとめ:自社に最適な予知保全の機械学習で「止まらない工場」を実現しよう
- 予知保全では、人・設備・コストの制約を超える手段として機械学習が有効
- 予知保全の適切な手法は、目的・データ量・現場環境で異なる
- 導入範囲は、まずは影響の大きい設備と特定の故障モードに絞ることが重要
予知保全では、技能承継の停滞や監視の限界、突発故障による損失といった人・設備・コストの制約を超える手段として機械学習が有効です。
適切な手法は、検知したい故障の種類や保有データ量、現場の計算環境によって変わります。まずは影響の大きい設備と特定の故障モードに絞って導入することで、ダウンタイム削減や歩留まり向上といった効果が期待できます。
予知保全に機械学習を導入すべきか検討中の方は、お問い合わせフォームよりお気軽にご相談ください。


